HALMA
Humanlike Abstraction Learning Meets Affordance in Rapid Problem-Solving
The HALMA Game
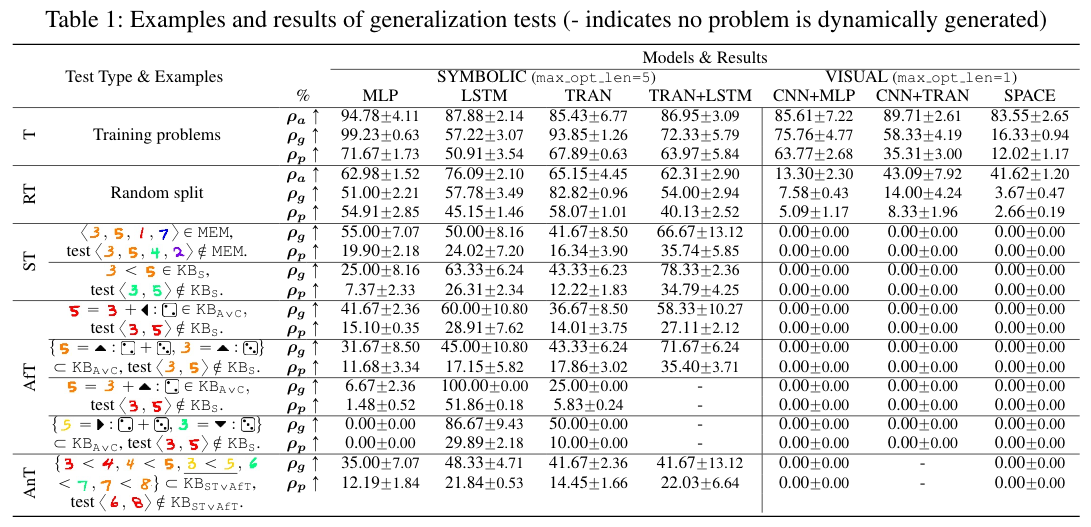
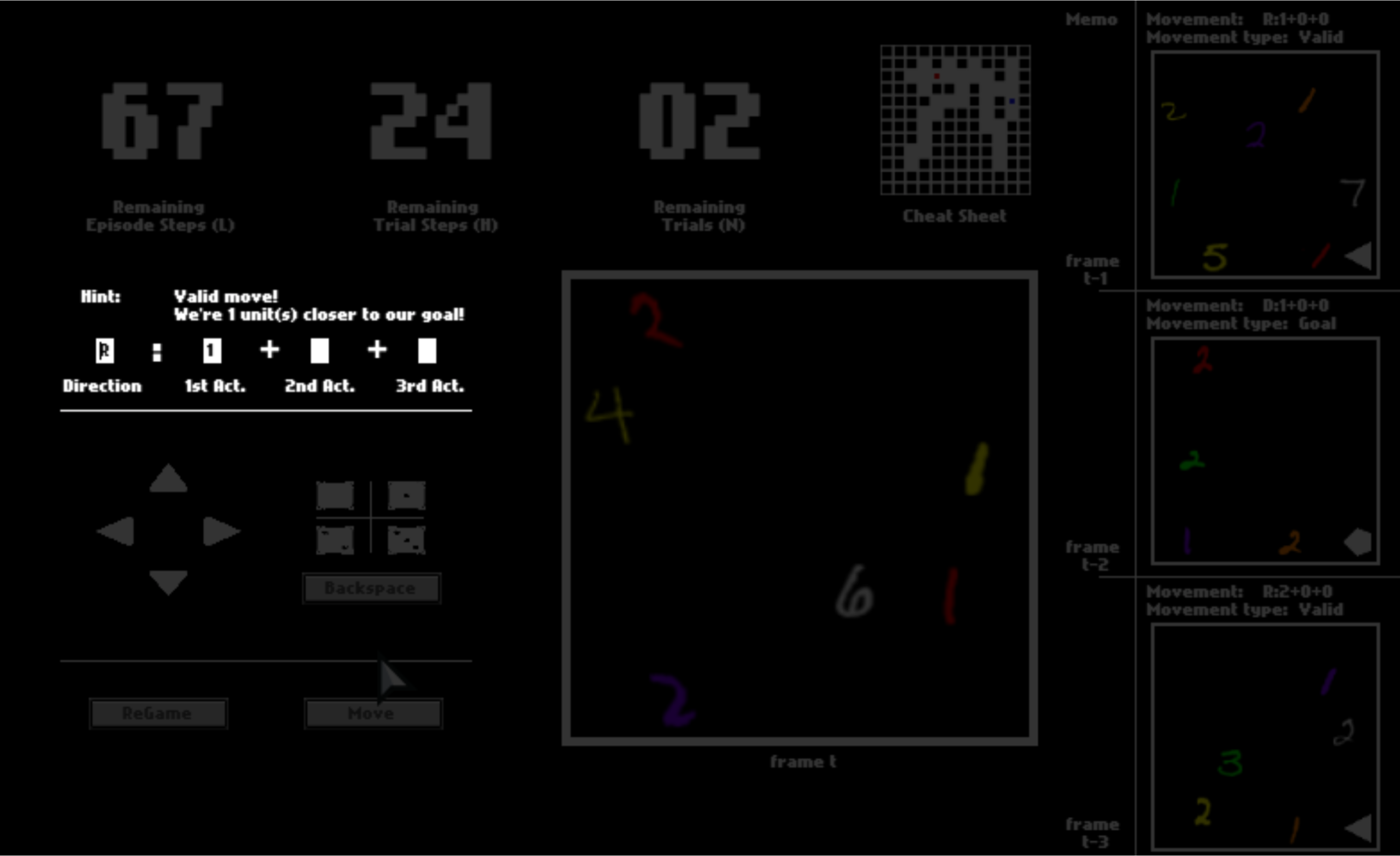
Imagine you are in a dark space where you can see almost nothing. The only things you can see are colorful digits and some geometric symbols, as shown in this panel.
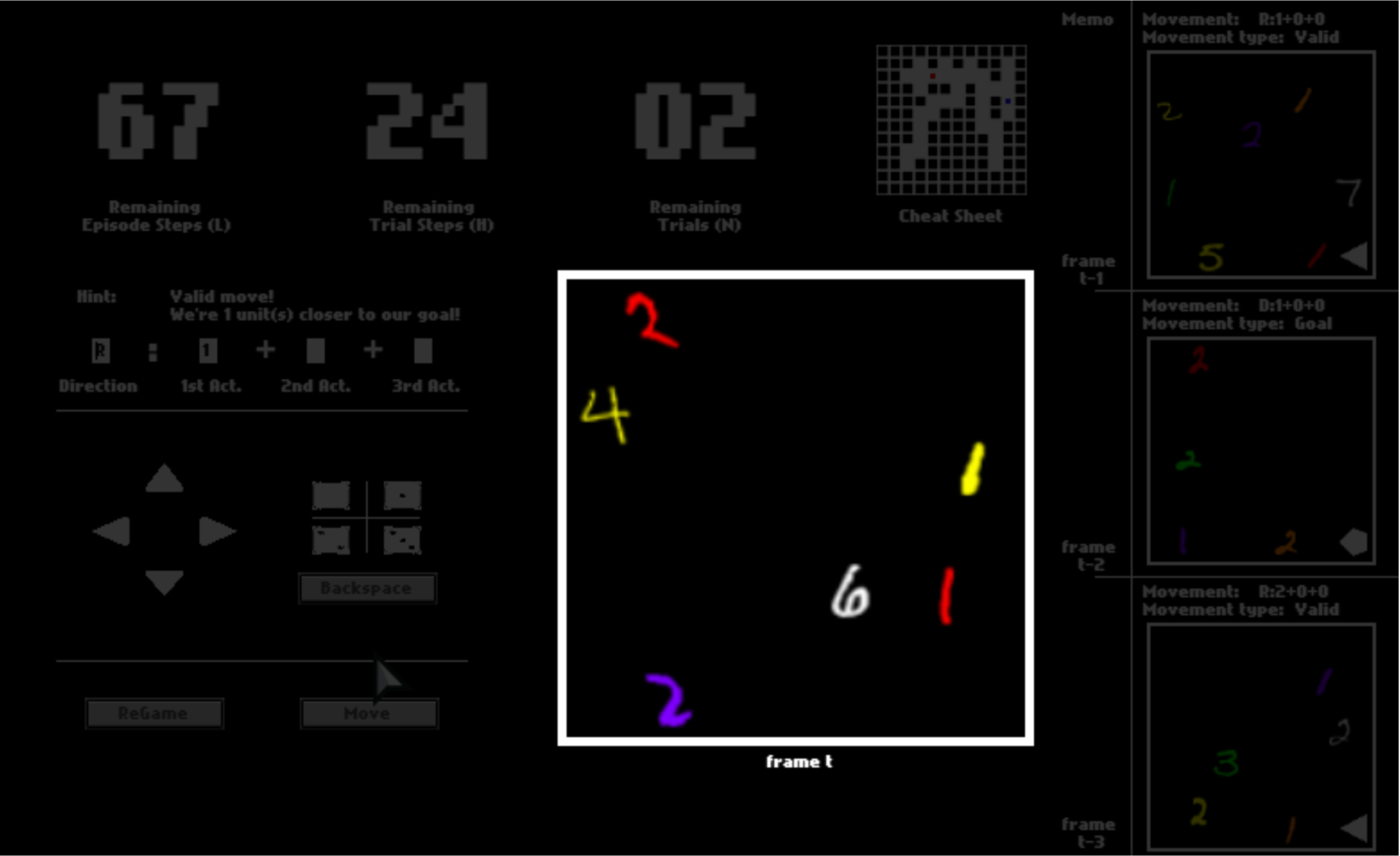
Meanwhile, you can make some moves to travel around the dark space. These moves are somehow “magical” because you may do a catapult-like instant transition after you make a decision. Specifically, every time you want to make a move, you first pick a direction from {  ,
,  ,
,  ,
,  } and then a sequence of primitive actions from {
} and then a sequence of primitive actions from {  ,
,  ,
,  ,
,  } with replacement. For example, you can pick for direction and + for the sequence of primitive actions.
} with replacement. For example, you can pick for direction and + for the sequence of primitive actions.
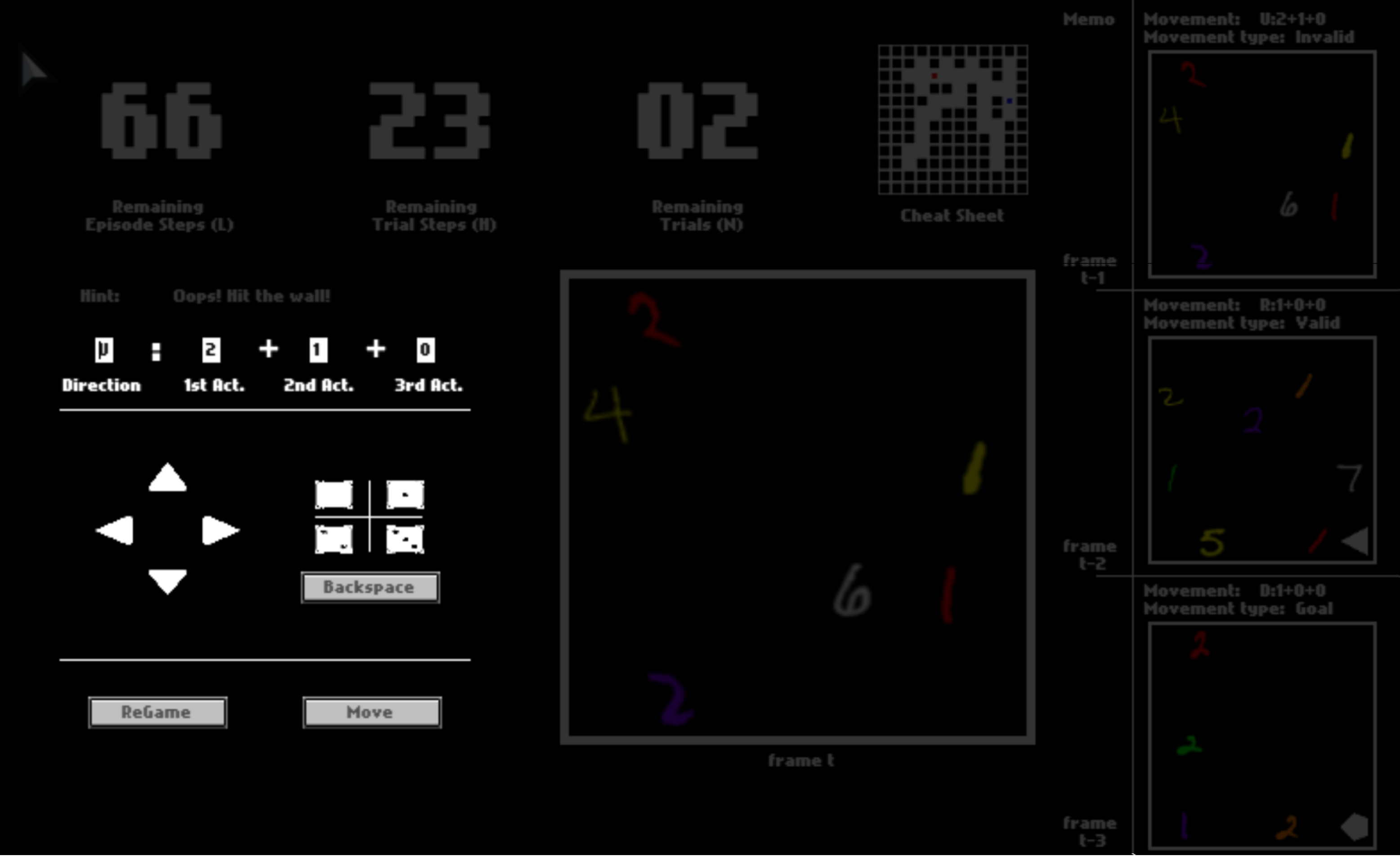
Action sequences may vary in their length. Here in this console, we constrain the maximum length to be 3. Action sequences do not have to be of the maximum length, thanks to the End of Sequence (EOS) token . That is, after you pick this token for a certain action in the sequence, all following actions will be automatically set to be .
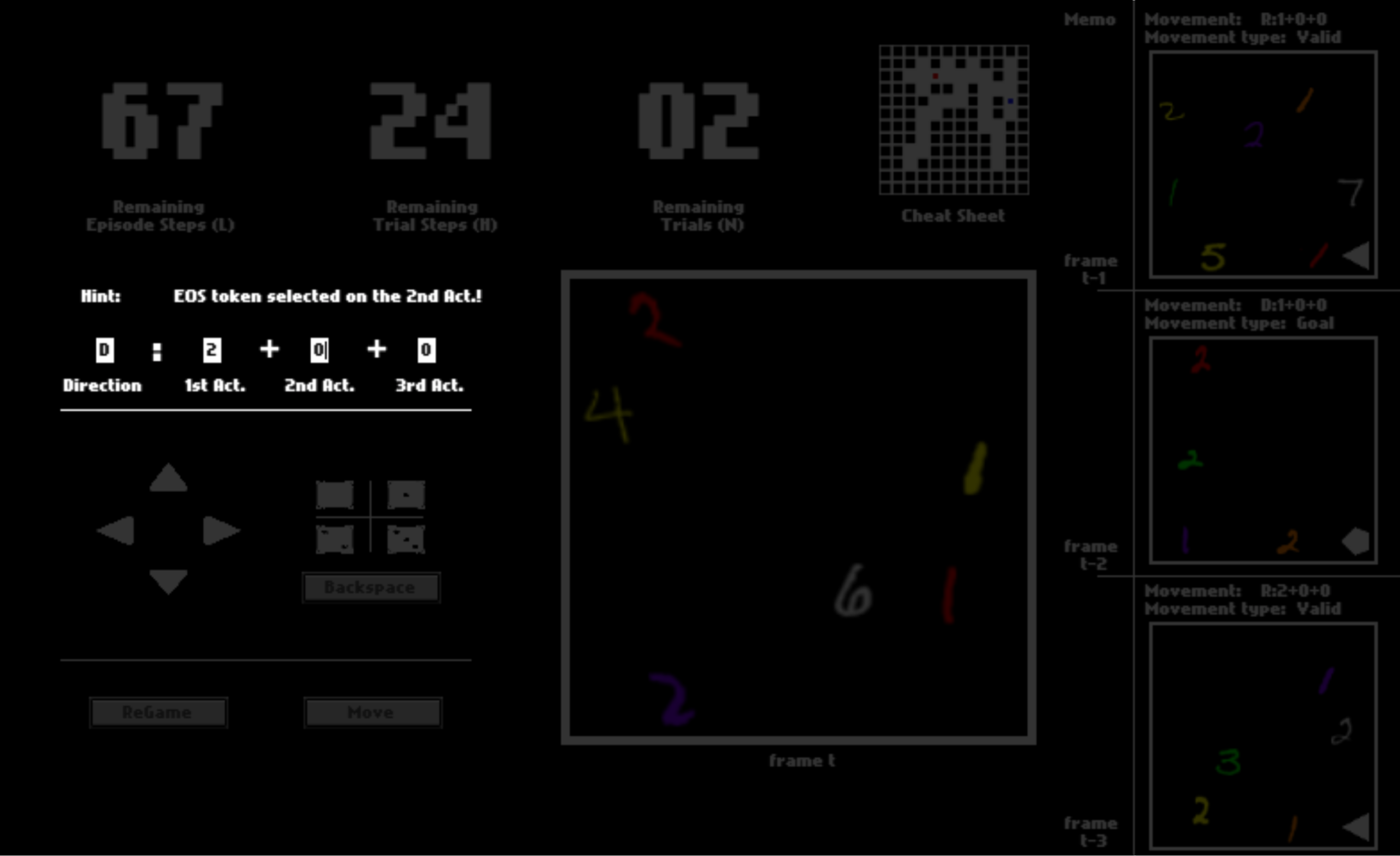
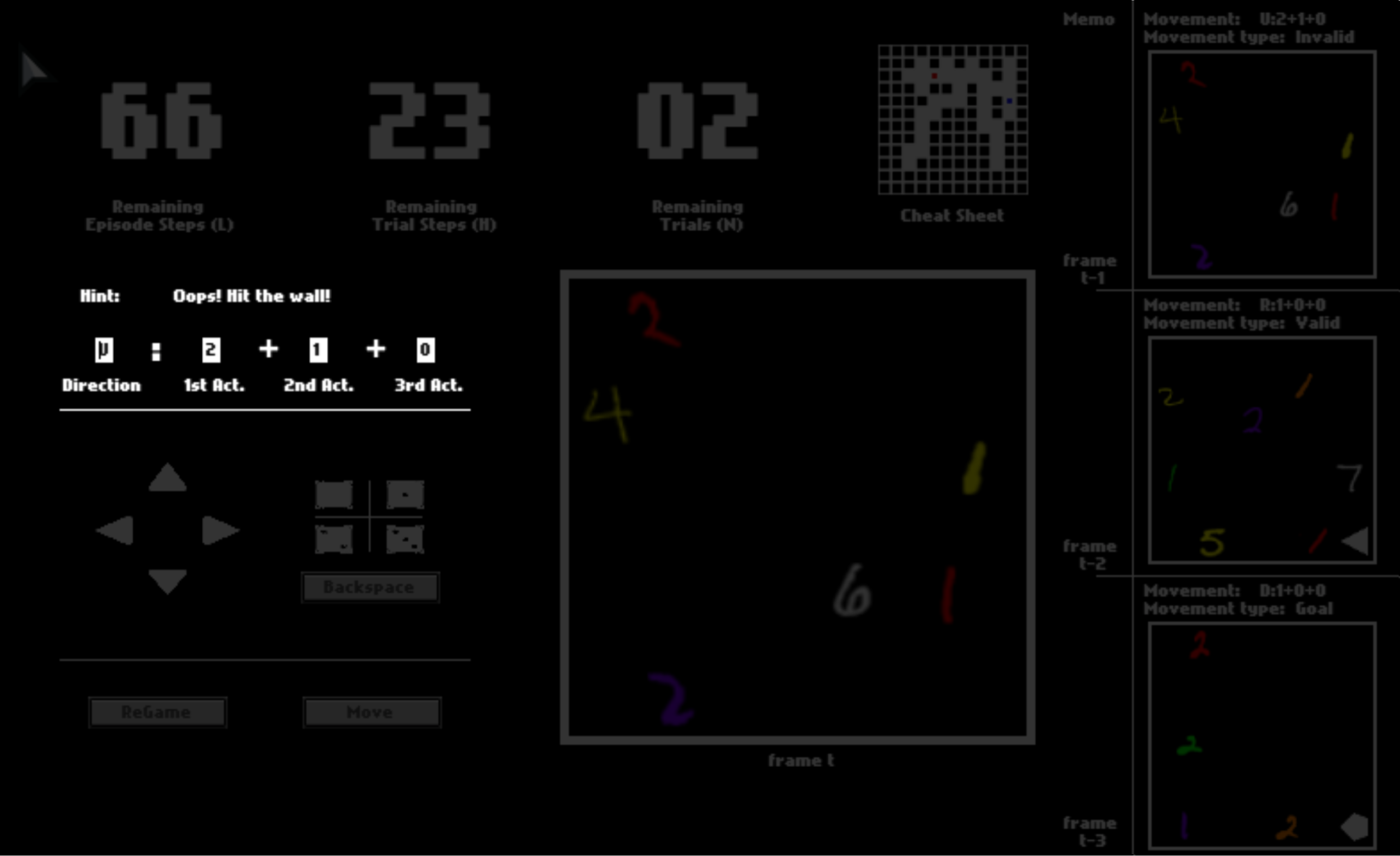
After you click “Move”, the option may or may not be executed, depending on whether it is valid (affordable) or not. If the move is executed, you will be instantly transited to the next position. Otherwise, you will stay where you currently are.
To help you memorize your previous panels and moves, your last three panels are presented to you. They may help you to understand this game while playing.
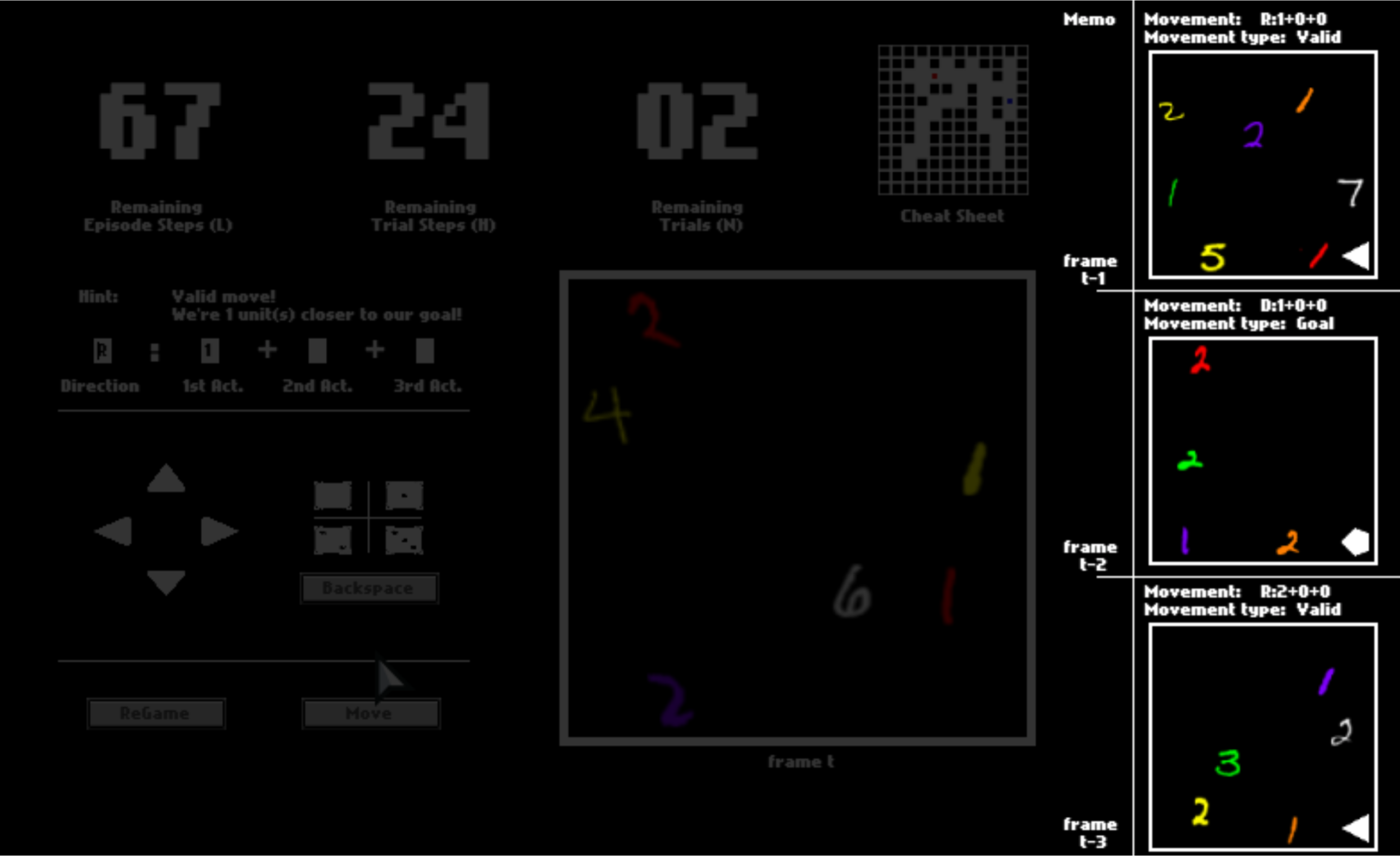
There are three numbers on the top, tracking the remaining number of steps in the current trial, the remaining number of trails, and the remaining number of steps in the current episode. You can equal “trials” in the HALMA game with “lives” in Atari games, and “episodes” with “levels”.
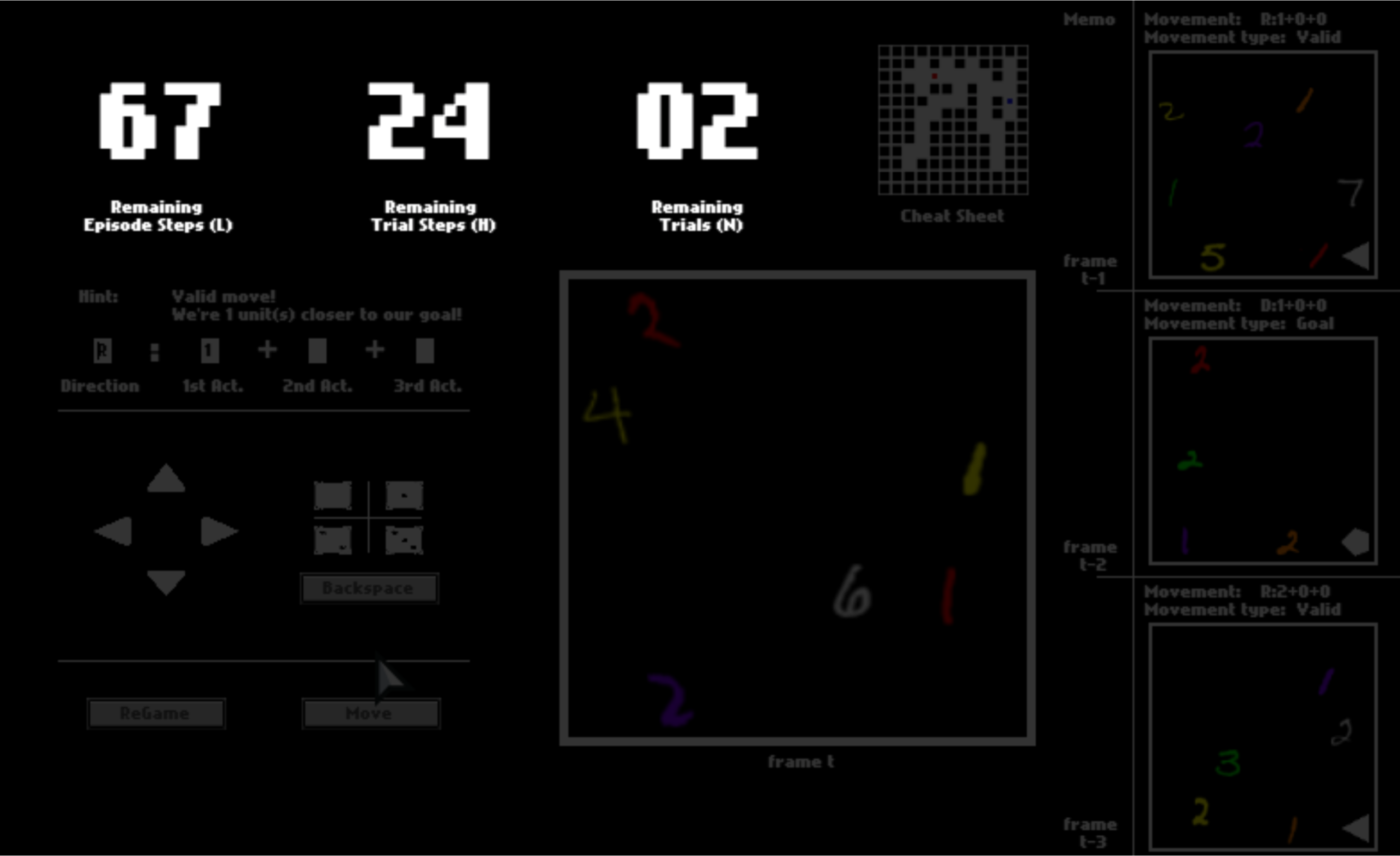
After one trial ends, you will be respawned to the initial position and start a new trial in the same space. You will have 3 trials in total. You will be scored by how fast you pass one trial, that is, how many steps you use on average.
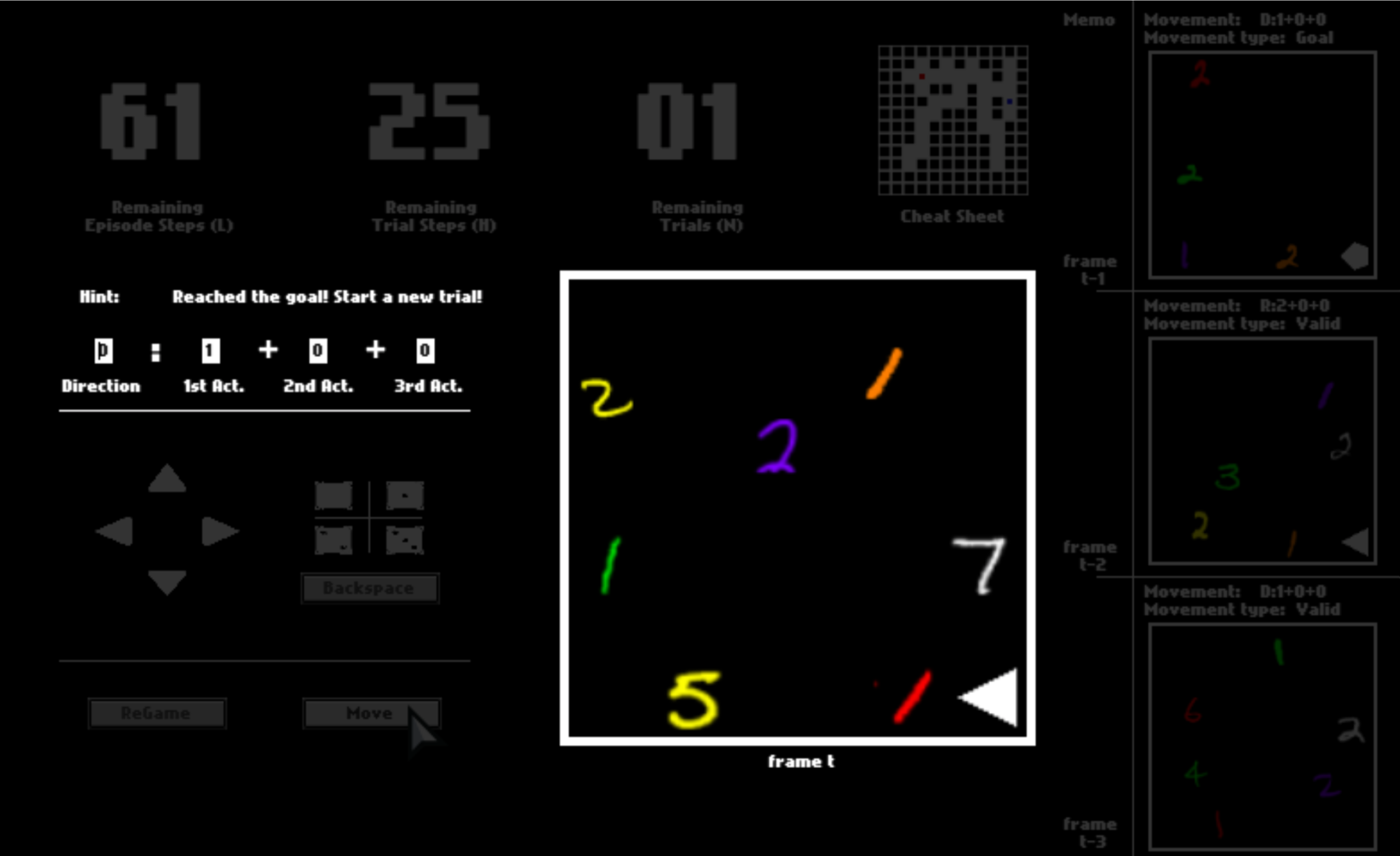
To help you understand this game, we provide 11 training mazes below. You can try them out parallelly.
Episode 1
Episode 2
Episode 3
Episode 4
Episode 5
Episode 6
Episode 7
Episode 8
Episode 9
Episode 10
Episode 11
Generalization Tests
Now let’s test how you can generalize your understanding to a new maze. Remember that your will be scored based on how many steps you use in each trial. Also remember that in this episode, the maze, you initial position, and your goal will stay the same in all three trials. We measure the average number of steps across these three trials
Congrates again on passing this test. You beat the best of current AI by a large margin!